
2025-05-26

浏览量0
分享
在第五届焉知汽车年会“智能辅助驾驶论坛”上,魔视智能乘用车产品副总经理张峥以《智驾模型的泛化思路》为主题,深度剖析了智能驾驶技术的演进逻辑与核心挑战。
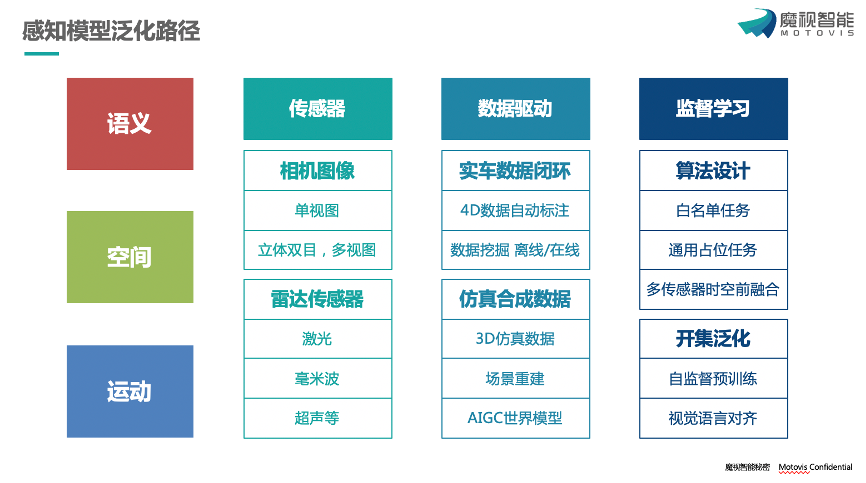
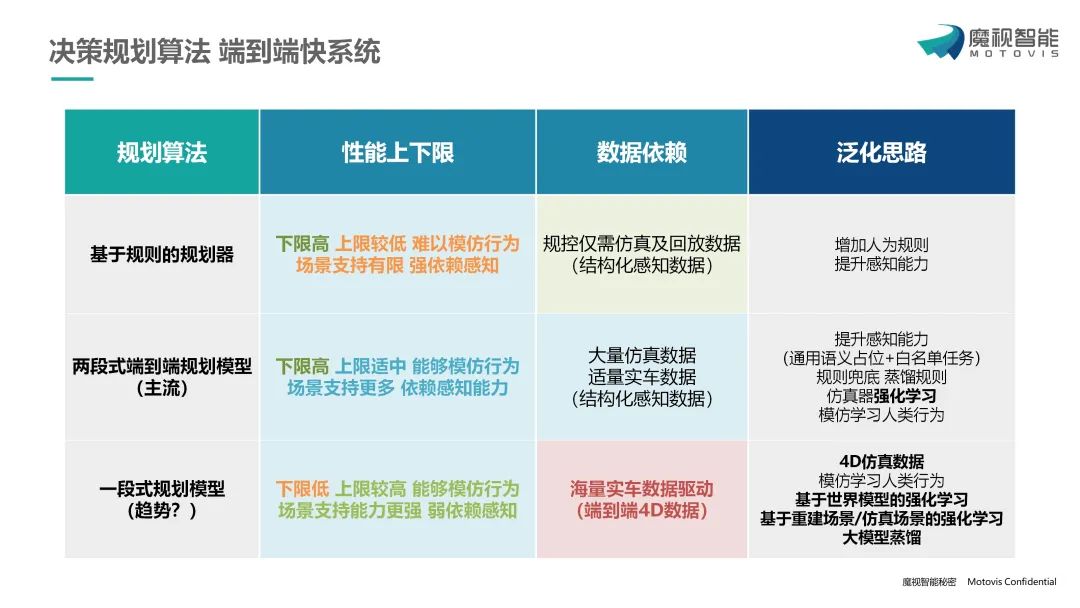
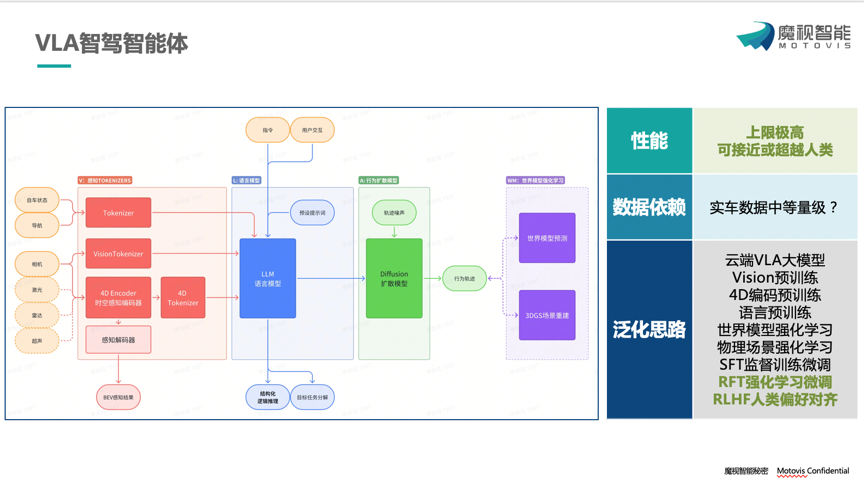
魔视智能 乘用车产品副总经理 张峥主题演讲 作为深耕智驾领域多年的先行者,魔视智能以“泛化能力”为突破口,提出从感知升级到认知觉醒的全链路解决方案,为行业提供了应对复杂场景、突破数据瓶颈的新思路。 张峥 张峥指出,感知模型的泛化能力是智驾系统的基石。魔视智能通过 “传感器性能+数据驱动+算法进化”三位一体路径,构建全方位的环境理解能力。 传感器融合创新 打破单模态局限,整合摄像头、激光雷达、毫米波雷达等多传感器数据,通过多模态时空前融合算法,实现语义、空间、运动信息的精准捕捉。 4D数据治理体系 自主研发自动化标注工具与大模型挖掘技术,实现场景元素的高效提取与失效案例闭环,结合3D资产库与AIGC生成,破解长尾数据难题,降低数据边际成本。 算法迭代进化 从单模态白名单任务到通用感知任务,引入开集数据自监督预训练与视觉语言对齐,提升模型对未知场景的适应性。 张峥 在决策规划层面,魔视智能提出了分阶段泛化策略,兼顾性能上限与落地可行性。 规则优先,夯实下限 基于结构化感知的经典规划器,通过仿真数据快速验证规则逻辑,确保基础安全性与功能稳定性。 两段式端到端,模仿人类 以感知结果为输入,结合强化学习优化类人驾驶行为,平衡规则与数据驱动的优势。 一段式端到端,突破天花板 探索感知-决策-控制一体化模型,依托3DGS场景重建与虚幻5仿真环境,生成高多样性数据,结合强化学习挖掘模型潜力。 张峥 张峥表示,当我们面对数据驱动的局限性,魔视智能将目光投向视觉语言行为(VLA)范式——一种更接近人类认知的智能体架构。 VLA的核心优势 通过视觉模块、语言模块、行为模块的协同,赋予智驾系统常识推理与交互学习能力,减少对海量数据的依赖。 认知觉醒的关键 基于R1强化学习范式,利用少量数据微调即可实现跨场景泛化;通过世界模型+人类偏好对齐,让VLA在非同源环境中快速适应,甚至超越人类司机的表现。 云端到板端的落地路径 先在云端训练大模型,再通过知识蒸馏部署轻量化板端模型,兼顾性能与算力效率。 从多模态感知到VLA智能体,在这场技术与认知的双重革命中,魔视智能已率先迈出关键一步,不仅展现了其对技术趋势的前瞻洞察,更揭示了 “以认知驱动泛化”的战略版图。 未来,魔视智能持续探索智能驾驶边界,逐步构建更像人、更聪明、更高效的智驾生态体,为行业打开认知智驾的新纪元。

关于北京国际汽车展览会 北京国际汽车展览会(Auto China)自1990年创办以来,历经30多年的发展,成为中外汽车行业的重要展事活动和中国会展业的标志性品牌展会,是在中国举办的国际最高级别的A级车展。2026北京车展不仅在场馆硬件条件上全面升级,而且在服务上也将全面提质,必将成为全球瞩目的车展新标杆。 2026(第十九届)北京国际汽车展览会,将以“领时代,智未来”为主题,于2026年4月24日--5月3日在北京盛大举行。





