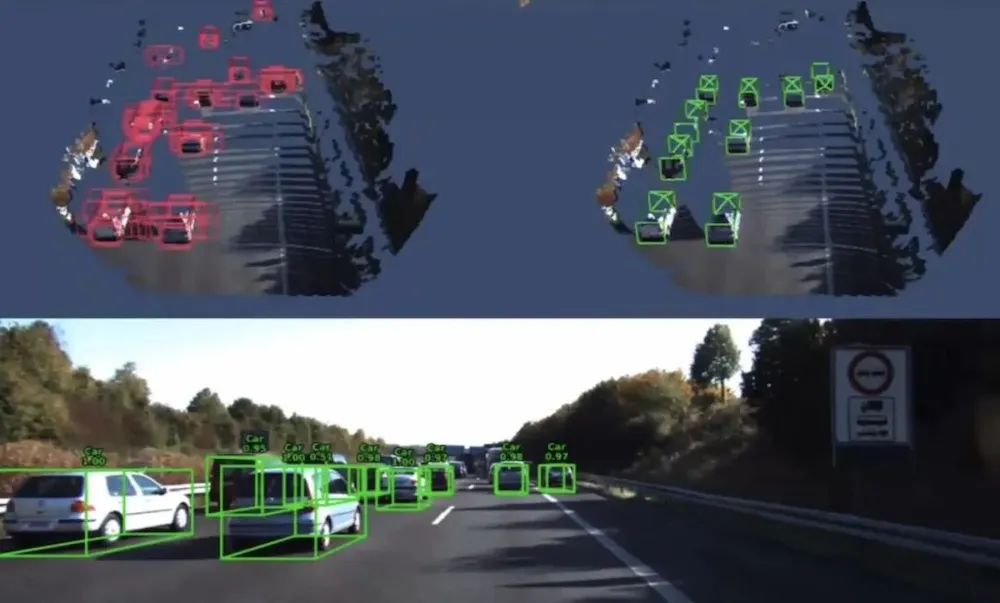
11月28日,智界S7正式上市。作为华为与奇瑞合作的首款车型,从诞生之初便引起了不小的关注。值得注意的是,这款车与问界M5、M7一样,都只装配了一颗激光雷达。在高端车型上将激光雷达数量减少至一颗,说明在华为的智驾方案中,单激光雷达已然足够。从2022年首次有合作车型上市以来,华为智驾方案的激光雷达数量从三颗逐步减少至目前的单颗。与此同时,华为智驾方案也经历了从ADS 1.0到ADS 2.0的演变。华为的选择,是智能驾驶终于走出堆料时代的一个缩影。本文详解华为的智驾方案,以及GOD网络可能的技术原理。硬件方案上“灵魂减配”的背后,华为智能驾驶同样面对传感器融合的难题,尤其以激光雷达和摄像头的融合挑战最大。11月26日,华为智能驾驶核心业务将建立合资公司的方式曲线实现“独立”,那么ADS 2.0方案,真的成熟到可以独自成长的地步了吗?
从华为智驾到鸿蒙智行,华为的智驾方案经历过从 ADS 1.0 到如今ADS2.0的演变。1.0时代,智能驾驶的未来路线还不太清晰,从各种传感器到高精地图,华为可以说把能想到的都用上了。比如在2022年4月首次合作推出的极狐阿尔法S HI版上,这款车配备了三颗激光雷达,相似的硬件配置方案,也用在了同年8月推出的阿维塔11上。智驾硬件上的堆料,直接推高了车的终端售价,两款车最终定价都触及了40万元的高位。但智驾堆料堆出了高定价,堆出了汽车品牌追求的高端产品,却没有为智能驾驶用户体验的落地铺出路来。包括华为在内的智能驾驶研发团队一直没有解决的一个问题是,这些五花八门的传感器之间,所面临的“语言不通”障碍。多传感器的融合是十分困难的,其中最有代表性的就是激光雷达和摄像头的融合。前者提供点云信息,后者直接给出图像信息。激光雷达的工作原理是这样的:通过发射脉冲光束,测量光束触碰周围物体后所反射回来的时间,由此来计算被测物体的距离。它的好处是精准和适应性强,可以达到毫米级的测距精度。可以在各种环境中使用,包括光照强烈和恶劣天气。虽然可以准确的感知周边环境的三维信息,但激光雷达只能提供稀疏特征数据,行业里称之为“点云信息”。而摄像头却能直接采集出图像信息,提供给系统算法,自动分析图像并识别出其中的各种物体,由此来更精准的做出驾驶决策。
▲激光雷达与摄像头的差异
也就是说,激光雷达虽然精准可靠,但无法单独支撑智能驾驶功能的迭代。如果华为不想像特斯拉一样走向纯视觉的方案,多传感器之间的融合,是必须解决的问题。如何做好传感器之间的融合一直是个难点。目前行业中探索的主流融合方式之一,称为点级,这套方案,需要将激光雷达和摄像头在车上的位置,进行高质量校准,极其精密的对齐,才能让两者的内容完全重合,如此来实现两组传感器的之间的“硬关联”。但这是一套脆弱的融合方式,如果车辆行驶中产生的颠簸,让传感器发生轻微的位移,那很小的误差也会造成对齐失败。此外,这种融合方案会浪费很多数据。比如激光雷达所采集到的稀疏矩阵数据,在与摄像头这种稠密矩阵数据进行融合的时候,会浪费大量具有丰富语义信息的图像特征。另外在图像特征质量比较低的时候,性能会大幅度下降。今年4月16日,华为发布了自己的BEV+Transformer+GOD方案,为如今华为更成熟的ADS2.0方案打下了基础。与特斯拉的纯视觉不同的是,华为在传感器硬件上,依然保留了一颗激光雷达,采用的是多传感器融合的方式。那在这个方案之中,华为是如何解决激光雷达和摄像头的融合问题呢?对于GOD技术的细节,华为没有做特别详尽的解释。但我们在2022年华为与香港科技大学、香港城市大学发布的这篇论文里,可以看到华为解决激光雷达和摄像头融合问题的一些可能的方式。首先通过激光雷达的点云数据,初步获得行车环境的特征图,再基于特征图,用Transformer结构的解码器,预测一个初始边界框,大概的将行车环境中,所需要注意的物体框选、标注出来,得到含有距离信息的边界框。到这一步,系统仍然处理的是激光雷达所采集到的信息,处理完激光雷达的信息后,系统会将这些信息投影到摄像头采集到的图像上,把2D图像的特征融合进去,给边界框赋予语义信息。这里面很重要的一个工具,是大模型Transformer,它能够自适应地寻找2D图像与3D点云的关联。对硬件的对齐要求也没那么高了。通过Transformer,华为可以让雷达和摄像头,两个传感器之间的硬关联,变成了软关联。这样就可以得到一个包含详细距离信息,系统又能看得懂的感知数据了。为了提高对小物体检测的稳健性,系统再次导入整个高分辨率的图像。通过Transformer中的交叉注意机制,以一种稀疏到密集的、自适应的方式将2D图像再次融合。使得系统能够自适应地确定,应该从图像中获取哪些信息,包括信息的位置和性质。来对之前的边界框进行增强,让小物体的识别更加精准。解决了传感器融合的问题后,华为就能让GOD网络获取更加丰富的感知数据,能帮助神经网络模型更好地感知和理解车辆周围环境。再通过GOD网络自主学习,构建3D世界模型。
华为为什么要大费周章的建立GOD网络,而不是像特斯拉一样,采用一套纯视觉的智能驾驶方案呢?事实上,华为乃至整个智能驾驶行业,都没有停止对特斯拉的学习。2021年,特斯拉FSD Beta开始采用了一套基于BEV+Transformer的智能驾驶方案,BEV即鸟瞰图,它就像是为智能驾驶打开了一个从空中俯视上帝视角,让车辆能够把近处的感知统一放到一个平面中。特斯拉的方案,为华为和其他埋头苦干的智驾公司,提供了另一种思路,华为在ADS1.0时代,也采用了这项组合技术。但BEV框架还是不能解决所有问题,智驾系统需要先识别面前的是什么物体,才能做出相应的决策。如何识别前方物体呢,就需要依靠大量的系统训练,将一个个识别成功的物体,放进智驾系统所建立的“白名单”中。可是“白名单”不足以覆盖实际交通环境中出现的海量障碍物类型,真正复杂的交通场景下,白名单永远都填不满。另外,感知系统只能识别到之前见过的物体,而没有办法识别一些异形的物体。
▲BEV视角下的点云信息
这项技术有一个硬伤,就是鸟瞰图是一套只有横纵坐标的二维图像,无法在Z轴上,感知到高度信息。也就是说,特斯拉的这套方案可以让姗姗学步的智能驾驶走起路来,却还是不能保障走路时不摔倒。特斯拉很快找到了自己的解决方法。2022年的特斯拉AI Day上,OCC占用网络被引入,它通过大量的分析和训练,将多个摄像头提供的2D图像信息,在3D空间中还原。用无数个小体块来展现现实世界。但到这一步,国内智能驾驶方案商却跟不上了。实际上,纯视觉FSD真正的难点在于海量的驾驶数据,除了采集数据,更需要一个强大的模型,来对智能驾驶方案进行训练。特斯拉自研芯片和Dojo模型,外购GPU将云端算力堆到10 Exa-flops,就是为了处理大量的传感器数据,并进行深度学习和模型训练。如果国内智能驾驶方案商贸然模仿,自家智能驾驶技术进步速度,可能永远也追不上特斯拉,华为不甘心只当一个追随者。原本国内的新势力们解决这个问题的方式是依赖高精地图。在发现高精地图因为成本和更新不及时的问题,而无法长久应用后,大家纷纷开始研发自己的方案,华为就是其中之一。华为所建立的多传感器融合方案,就是为了避开特斯拉OCC花在将2D图像还原成3D,所需要的那部分复杂计算。通过加上一颗激光雷达,提供更加详细的距离信息,华为降低了数据分析的难度,对云端算力的需求也相应降低。此外,在国内复杂的城区路况下,对近距离测距的精准度要求更高,比测试场地中更棘手的case多很多。这颗激光雷达就可以对前方障碍物进行详细测距,再与摄像头的数据精准匹配,得到更为准确的数据。并且在暗光、大光比、雨雾天气这种摄像头识别不那么准确的时候,也可以稳定输出感知数据。虽然眼下华为保留单激光雷达的方案,在装车的硬件成本上,仍然会高于只有摄像头的纯视觉方案,但研发投入、时间周期,也是需要被计算的成本。如今,在华为智驾方案不断迭代的途中,特斯拉的纯视觉方案FSD已经很久没有披露出进展了。也许,融合激光雷达的智驾路线,“总成本”更低。

▲智界S7上市
智能驾驶方案迭代到现在,算法已经不是各家竞争的焦点。在数据量不足的时候,面对不同城市的复杂路段,难免出现漏洞。如何快速获取行驶数据,并在短时间内将训练结果OTA到车辆,才是加快开城速度的关键。从竞争者蔚小理的部署情况来看,也许明年,辅助驾驶的数据竞争赛,就要正式开始了。与这几家企业一样,华为计划今年年底开通全国的无图城区智能驾驶,压力一点都不小。按道理来说,辅助驾驶开通之前,车厂都应该用自己的车队跑一遍,给大模型的训练一个基础的数据。但全国都跑的话,需要耗费大量的时间和人力、算力。如果直接开通给用户,短时间内大量的数据涌入,也会让华为不堪重负。优先开通“通勤模式”,让各地的车主在同一路段反复跑,对大模型反复进行“自训练”,也许是比较稳妥的方式。华为的融合方案,就单车的硬件和计算成本来说,肯定是有所增加的。融合算法必须证明自己在“总成本”上更具性价比,才有可能被大规模的铺开。多去路上收集实战数据持续训练AI,才能让车辆越“开”越聪明。







